


沈阳自动化所机器视觉研究多篇论文获AAAI2026录用
近日,国际人工智能顶级会议AAAI 2026论文接收结果公布,中国科学院沈阳自动化研究所在机器视觉研究方面的多篇研究论文获录用。
在多模态大模型视觉生成方面,研究团队提出了一种专家表征对齐的多模态大模型训练框架ARRA,可有效促进大模型学习跨模态表征,实现多任务通用多模态生成。相关研究成果Unleashing the Potential of Large Language Models for Text-to-Image Generation through Autoregressive Representation Alignment被大会选为口头汇报(Oral)论文,论文第一作者为博士生谢兴,通讯作者为范慧杰研究员与屈靓琼助理教授。
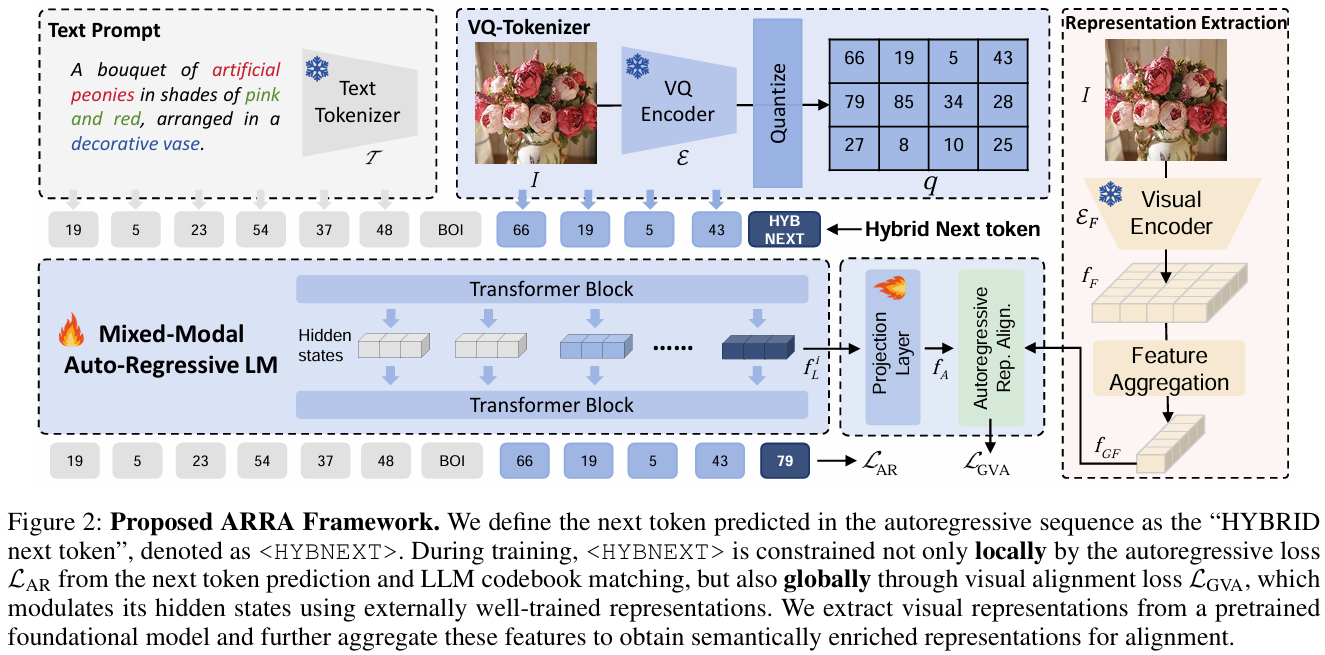
多模态大模型自回归表征对齐训练框架
在多模态大模型方面,研究团队提出了创新的物体分词框架ObjecTok,显著提升了模型以物体为中心的感知与推理能力。相关成果论文为ObjecTok: Learning Holistic and Robust Object Tokens for MLLMs,第一作者为博士生王思翰,通讯作者为刘西瑶副研究员。
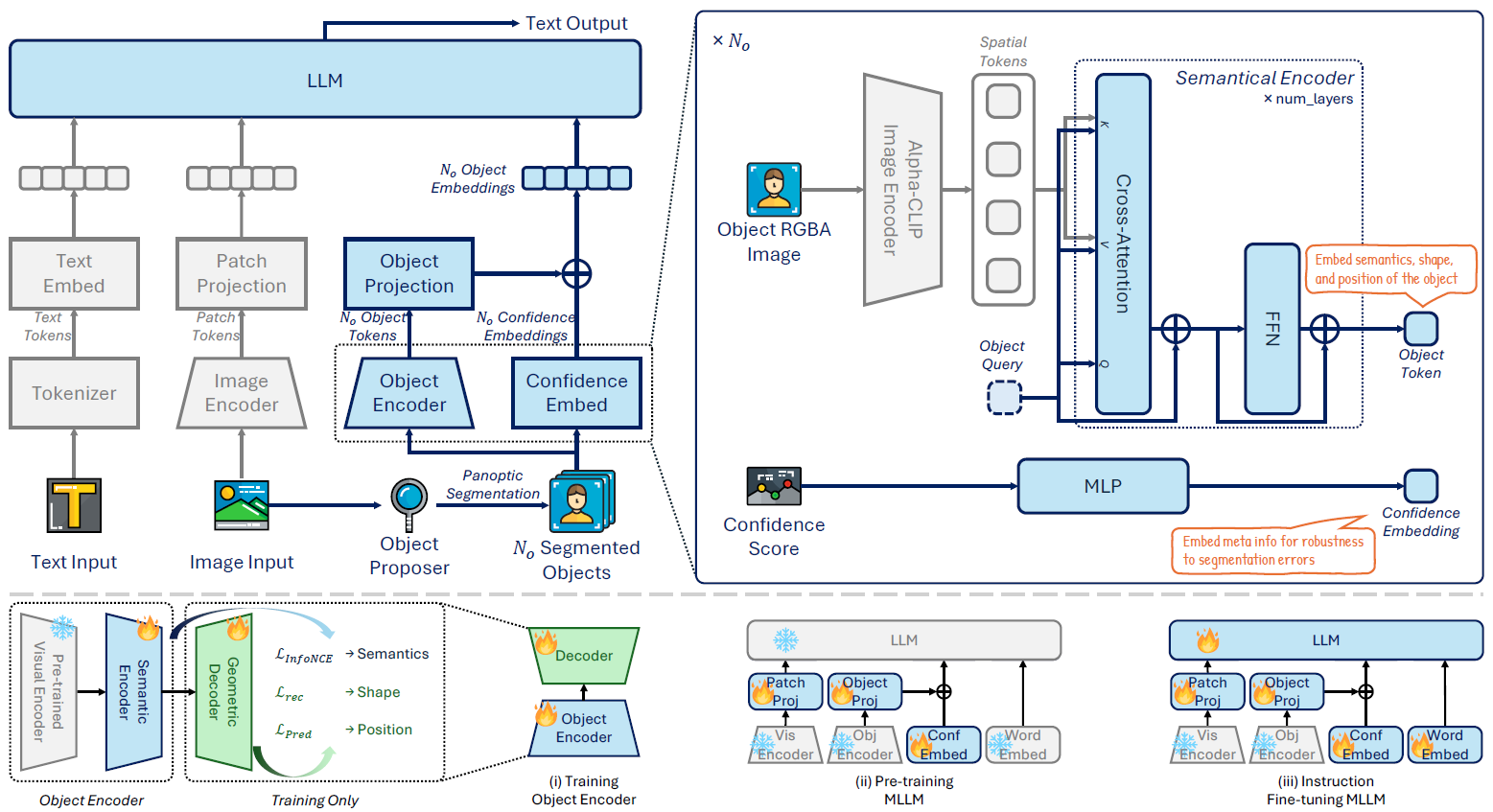
MLLM物体词元学习示意图
在具身智能操作方面,研究团队提出了一种仿人知识总结与继承的终身学习框架,赋予智能操作机器人持续演进、不断适应新技能的终身学习能力。相关研究成果论文为Lifelong Language-Conditioned Robotic Manipulation Learning,第一作者为博士生王旭东与沈阳自动化所实习生韩泽斌,通讯作者为韩志研究员。
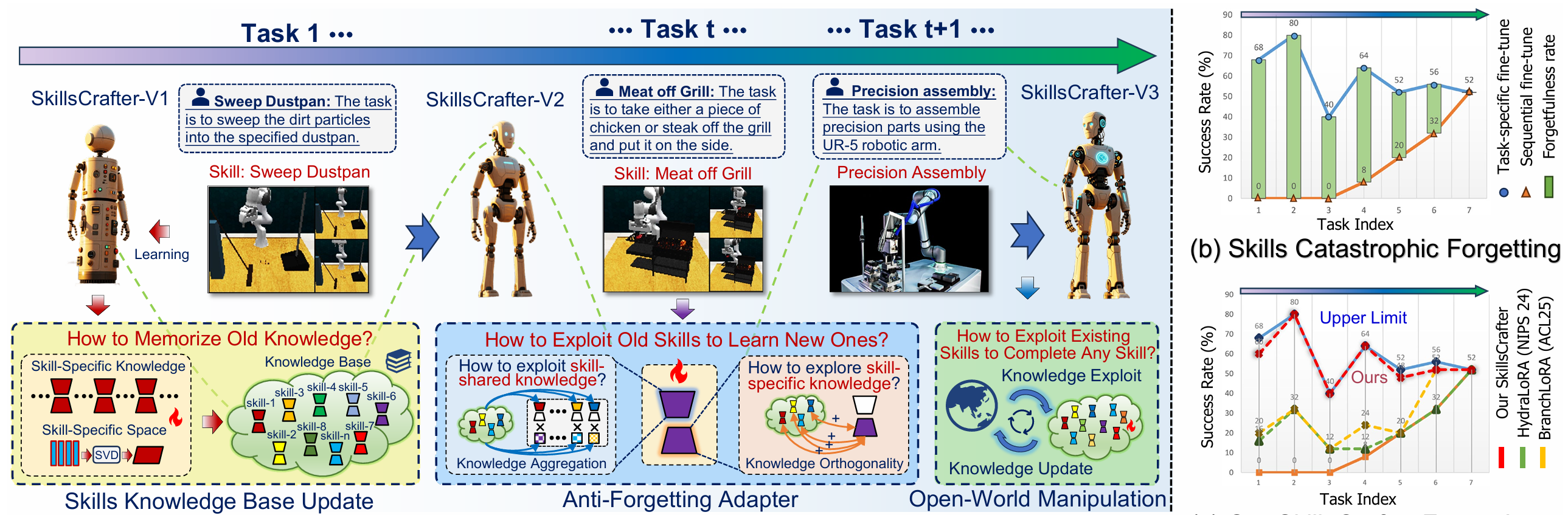
智能机器人多技能终身学习示意图
在具身智能导航方面,研究团队提出了一种基于分层规划策略的导航智能体,可提升智能机器人在复杂大场景中具身导航的鲁棒性。相关研究成果论文为SeqWalker: Sequential-Horizon Vision-and-Language Navigation with Hierarchical Planning,第一作者为沈阳自动化所实习生、中北大学本科生韩泽斌,通讯作者为博士生王旭东。
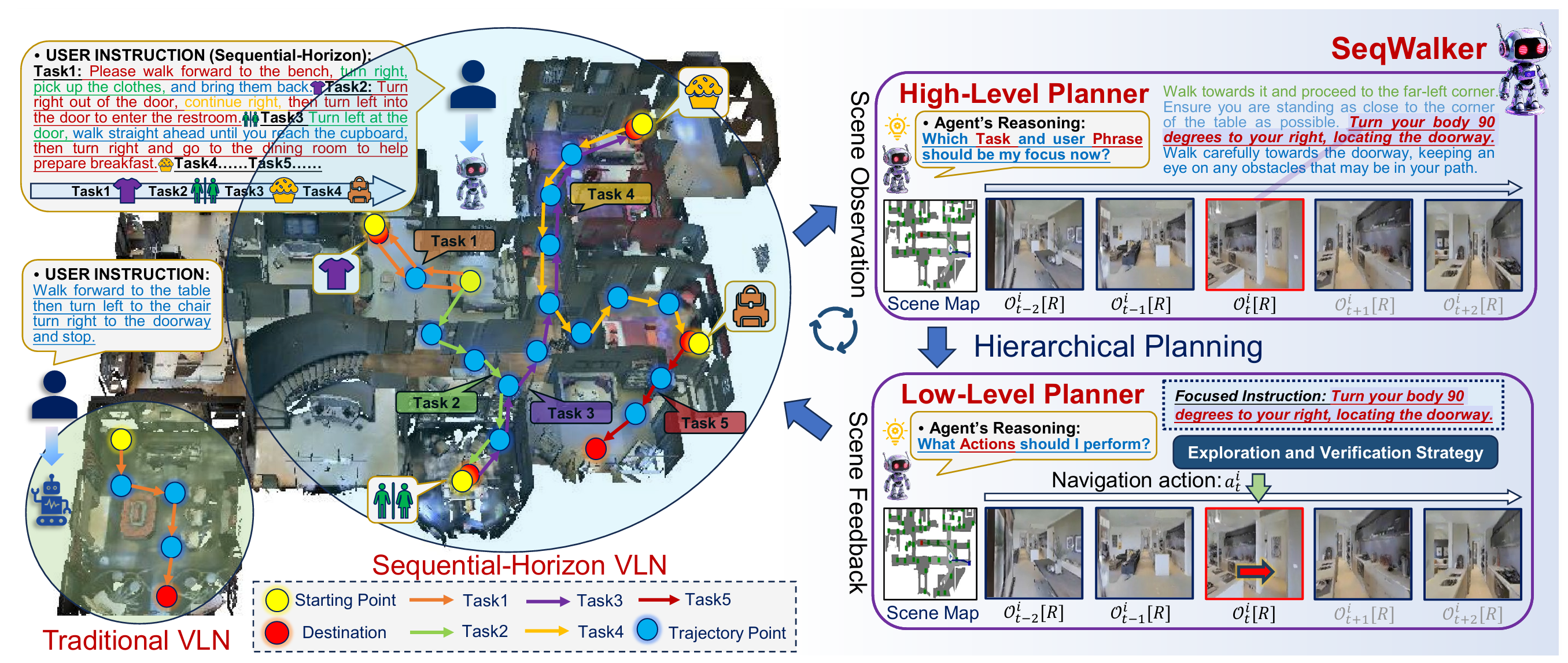
智能机器人大场景复杂指令顺序导航示意图
在视频定制化生成方面,研究团队提出了一种连续定制化视频扩散模型,可在连续动态空间中实现任意概念的个性化视频生成。相关研究成果论文为Bring Your Dreams to Life: Continual Text-to-Video Customization,第一作者为沈阳自动化所博士毕业生、穆罕默德·本·扎耶德人工智能大学博士后董家华和沈阳自动化所博士生王旭东,通讯作者为韩志研究员。

多概念持续定制化视频生成示例
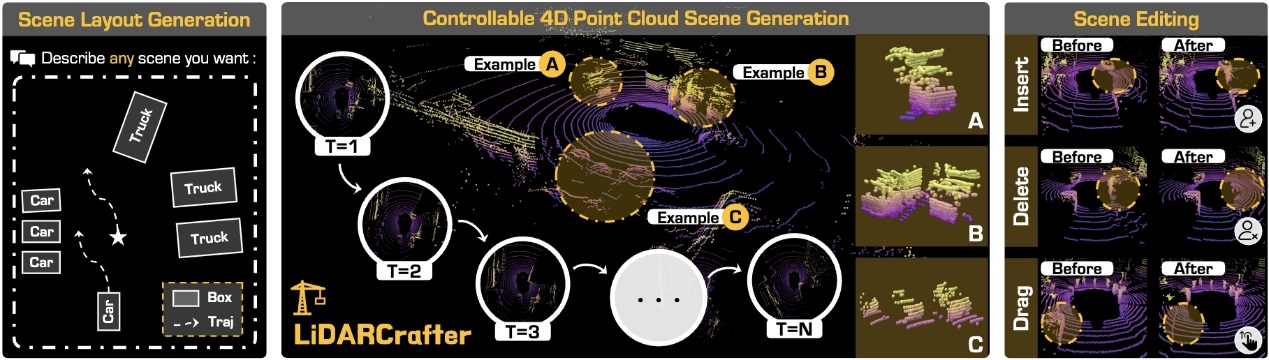
在生成式世界模型方面,研究团队提出了首个可用自然语言控制的 4D LiDAR 生成模型,实现了高逼真、可编辑的动态点云场景生成,可用于多种下游感知模型的安全验证和闭环仿真。该研究成果LiDARCrafter: Dynamic 4D World Modeling from LiDAR Sequences被大会选为口头汇报(Oral)论文,第一作者为博士生梁奥,通讯作者为赵怀慈研究员。
上述研究成果得到了国家自然科学基金、国家重点研发计划、机器人与智能系统全国重点实验室自主项目、沈阳自动化所基础研究项目等支持。(机器人学研究室 光电信息技术研究室)
附件下载:




