


神奇的立体视觉
最近几年3D电影越来越受欢迎,几乎可以说是“无3D不电影”,3D电影远比2D电影更具吸引力。我们喜欢看3D电影,因为它比2D电影更让我们感到“真实”,换句话说3D电影具有“立体感”。那么我们是如何感受到这样的立体感的呢?这就是我们要讲的立体视觉。
我们通常所说的“立体感”靠一只眼睛是完成不了的,至少需要两只眼睛。当我们注视到某个物体时,我们两只眼睛的视线会自然而然的交叉于一点(斗鸡眼除外),这一个点有个很通俗的名字——“注视点”,从注视点反射回到视网膜上的光点是对应的(就像下面这两幅图片示意的一样)。
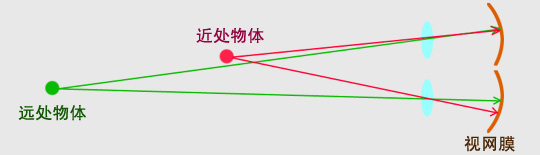
想象一下,两只眼睛上有这样许许多多的对应的光点会形成什么?当然是两幅对应的图像,当然这两幅图像仅仅停留在视网膜上是没什么意义的,视网膜会将这两幅相互对应的图像传送到大脑中的视觉中枢,然后我们的大脑会很自觉的将这两幅图像合成一个立体的像。这个过程并不易被我们察觉,所以我们一般情况下不会知道到我们两个眼睛各自看到平面图像到底是什么样的,却可以意识到 “立体的物体”。相对于一个2维图像,我们不但能看到事物,而且还会知道到我们观察的物体距离我们大概有多远,也就是距离感。当然还不仅仅如此,我们所得到的信息远比我们想象的要多的多,比如深度、凹凸等等一系列的数据。这也就是为什么我们通常情况下很容易快速抓住一个东西,但是当我们闭起一只眼睛后再迅速的抓取一个物体就不是那么容易了,因为我们一只眼睛看到的2维图像并不能告诉我们它到底在哪里!

这里我们要讲的立体视觉并不是生物的立体视觉,而是机器的立体视觉。日常生活中我们拍摄的图像通常是二维的,也就是我们通常的照片。这样的2维的像只能还原给我们拍摄者拍摄时从镜头里看到的景物是什么样子的,如果我想换个换个角度看原来的景物怎么办,想换个距离看又怎么办呢?肯定不可以在每个位置每个角度都拍一张照片。这时我们就需要想办法让机器像人的大脑一样得到一个立体的像,也就是我们要讲的立体视觉(上图为3D的方鼎图像)。
那么这样的机器的立体视觉是怎么实现的呢?回想一下我们讲到的人的立体视觉是怎么实现的?首先至少得有两个眼睛,而且这些眼睛所能看到的区域必须得重合,不然就不能有对应的视点了,当然也就不能产生立体视觉了(PS:像牛跟马一样眼睛长在两边的动物,两眼的视野是不重合的,所以只能看到2D的图像,生活在二维世界的生物是多么的悲催!!),那么这里我们就需要至少两个摄像头,这两只摄像头所拍摄的图像还必须有重合;其次人通过眼睛获得的图像是在大脑里产生立体的像的,在机器中就需要处理器和图像处理算法来完成这样的功能。说了这么多,还是那个问题:“这到底是怎么实现的呢?”
我们以双目立体视觉为例子,首先计算机通过两个不同位置的摄像头,获得两幅有视差的图像,然后利用一些列的图像特征提取算法,获取特征点,然后对两幅图像上的这些特征点进行匹配。是不是看的有点迷糊,其实这里说白了就是像前面所说的那样找到两个图像中的对应的视点,再通俗一点就是告诉电脑在第一副图像的中的物体A在第二幅图像中应该是在什么位置,虽然这样的能力对我们来说是再简单不过了,但是计算机实在是太“笨”了,必须通过一系列复杂的算法才能知道,而且在很多情况下这些算法还会失灵(幸好这样,不然机器人早就统治全人类了)。
那么得到了这样的一对一对的匹配点又有什么用呢?因为计算机获得的两幅图像是有视差的,所以同一个物体在两幅图片的角度、位置甚至大小都是不一样的,正是利用了这样的差异,我们可以通过映射关系得到他们的映射矩阵,然后利用映射矩阵把二维图像中的点还原到三维空间中去,从而得到了三维的像。好吧,如果你对一些映射几何的一些知识还不是很了解的话肯定又晕了,这里我们再通俗解释一下,我们得到了两幅图像的匹配点,就好比知道了在不同位置的人看到了的相同的物体,如果我们想知道这个物体具体在什么位置怎么办?如果知道了两个人的相对位置(两个摄像头的距离)和各自观察物体的角度(也就是摄像头拍摄物体的角度),根据中学时我们学过的相似三角形的知识就能找到一个比例关系从而求得物体的位置信息,这个过程也就是好比我们映射矩阵的求解和映射过程。
通过这些步骤我们就可以把简单的二维图像影射成一个三维立体的像(就像下面这幅图像一样,利用上边三幅图片建立了下边的三维立体像,我们可以拖动这幅图像从各个角度来观察图像中的这尊石佛)。

目前除了双目立体视觉之外还有很多的立体视觉的方法,但是大致原理基本相同。目前这项技术现在已经逐步走向成熟,在很多领域都有很好的应用,比如盛产黑科技的谷歌公司正在将这项技术移植到手机上,想象一下,也许就在下一个月,你的手机就可以拍摄出三维立体的图像,这是多么的让人兴奋!(作者 沈阳自动化所水下机器人研究室 李雪峰)
附件下载:




